AWS Lambda cold start issue is going away soon?
Serverless technology is not any new any more. If you are already familiar with serverless technology and cold start issue, feel free to skip the following two sections.

What is Serverless?
A piece of code(or a function) that you want to execute in the cloud as and when you want it without having a dedicated server for you. Pay as you use is the most attractive feature of this technology and you don’t have any servers in the cloud that you need to protect and maintain.
Every cloud provider is now offering this solution. Here I am especially talking about AWS lambda. Any one who started adopting serverless will quickly hit with cold start issue.
What is cold start issue?
Here is a quick brief about what is cold start issue and why it occurs.
The very first invocation of a serverless function has to initialize a micro container to execute your specific function in an isolated runtime environment. It is really important to isolate this execution from the rest for the security reasons. This very first initialization of the micro container adds a delay in responding to your function invocation.
This delay gets even worse when you ask your lambda to be spawned with in your Virtual Private Cloud (VPC), which is the majority use case. It can range anywhere between 3 seconds to 15 seconds. But once it is initialized (we call this state as warm), it will respond quickly as there is no infrastructure work needed from there on. It just invokes your function code with in the spawned micro container. Overall execution time until you get any response from your lambda also depends on what you are trying to do with in your lambda.
Now the next important question. How long a lambda will stay in this warm state? The answer is definitely not forever and there is no right answer. As per AWS report, they stay active for about 5 mins in an open could space and for about 15 mins in a VPC (virtual private cloud mode) and again these times are not guaranteed because they are part of a shared execution pool.
AWS’ improvements for the Cold Start issue
There are 2 reasons why I think the cold start issue will become way less of an issue than what it is now, at least in the Amazon’s AWS cloud.
-
Improvements to the micro container technology, The firecracker.
-
Improvements spawning AWS Lambda instances within the VPC with a dedicated ENI (Elastic Network Interface) attached to your VPC.
Firecracker
The firecracker micro vm technology behind Amazon’s AWS Lambda has picked a significant improvement after they made it as an open source project back in 2018 which they announced in their 2018 aws:reInvent event. It’s already a year now that it is getting the ideas and improvements from the community. Apparently, the idea of a micro vm was initiated by Mozilla Firefox for spawning an isolated execution environment for each tab in its browser. They started the project development using Rust and it turned out to be a pretty good choice for the problem. You can learn more about this here.
Dedicated ENI
The second reason, the dedicated ENI attached to your VPC going to help the major use case of spawning the lambda within a VPC. This is also something that they promised in 2018 aws:reInvent event. You can watch their full presentation here but below diagram from their talk gives you a quick look at what this exactly means or you can read this post.
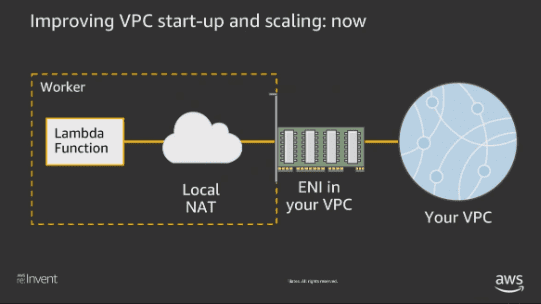
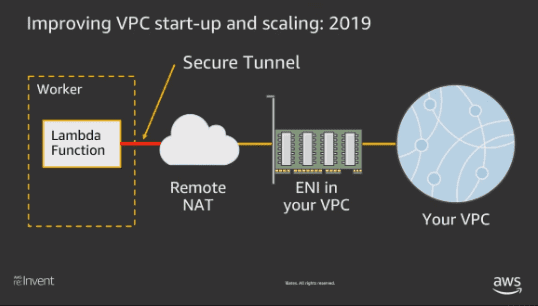
Since their promise, they have been working on this new architecture but we haven’t heard if they really rolled out this improvement until recently when they start to post their updates at this page. Their recent announcement explains that they rolled out this improvement in multiple regions. We were excited to read this announcement and really wanted to see how much these improvements help reduce the AWS Lambda cold starts with in a VPC.
Measuring these improvements…
Here is a small exercise we did to measure these improvements.
At the time of writing this post, improved VPC networking is only available in the following regions.
-
Ohio (us-east-2)
-
Frankfurt (eu-central-1) and
-
Tokyo (ap-northeast-1)
We added a region where the ENI enhancement is not rolled out yet to the above regions list. We picked Oregon (us-west-2) and replaced Tokyo from above list.
In each of the above regions, we created two lambda functions
-
One within a VPC and
-
Another without a VPC
To keep the test equal across the different regions, we kept all of them behind an API Gateway with two different end-points pointing to the above two lambda functions.
We were sitting in our East Coast Charlotte office while running this test so before we begin our test, we first started to measure the default latency of reaching to these regions. As per CloudPing.co following are the latencies.
-
Between Ohio and Oregon: 78.32ms
-
Between Ohio and Frankfurt: 102.73ms
So, that explains and also asking us to set a side around 25% of the overall latency to reach the Frankfurt region.
Test Results
Let’s get into the test now. Using jMeter, we triggered all the 6 APIs (2 per region) with 100 concurrent connections repeated 10 times and measured the response times. The results are exciting as you can see below.
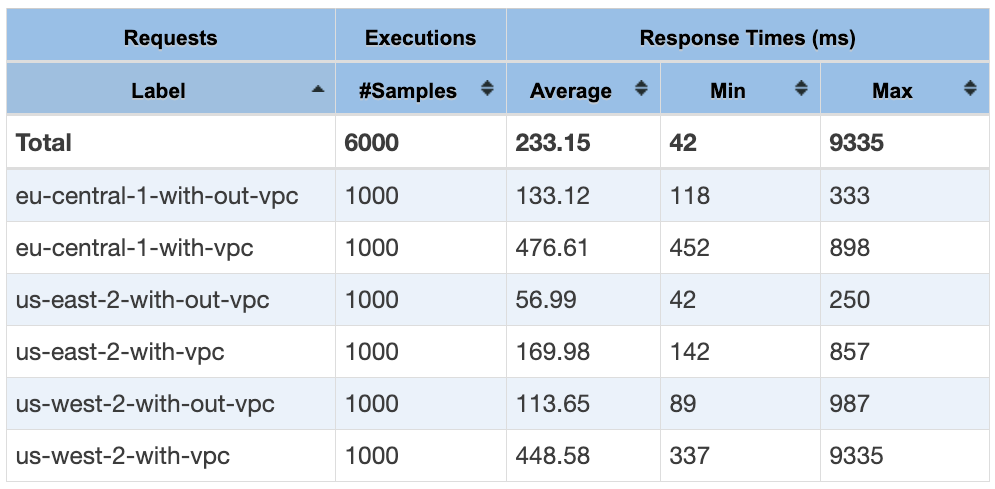
Comparison of maximum response times
Even with a higher latency to reach the Frankfurt region, when we see the maximum response times (in the last column), Oregon (us-west-2-with-vpc) took almost 9.3 seconds. Clearly shows the cold start delay and not having the ENI enhancements adding a major share to the maximum response time and making it significantly longer (9.3 seconds) compared to the other regions.
Comparison of overall response time
The second measurement we did is the percentile comparison of overall response time. Following is the overall response time chart that we got.

For this measure, we picked two versions of the chart to clearly explain the behavior.
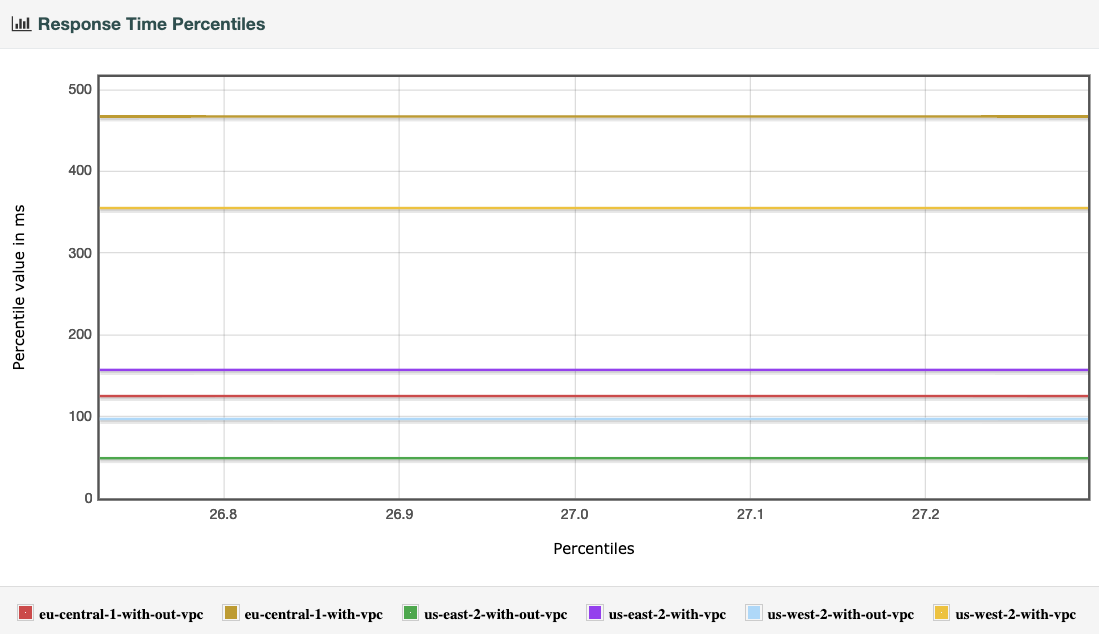
Around 27 percentile of the Chart
The first graph below is zoomed around the 27 percentile of the overall chart. Top 3 lines are for lambda with in a VPC and bottom 3 are for lambda without a VPC perimeter showing the obvious impact of within VPC vs without VPC.
Around 98 percentile of the Chart
Now let’s see the graph zoomed around the 98 percentile.
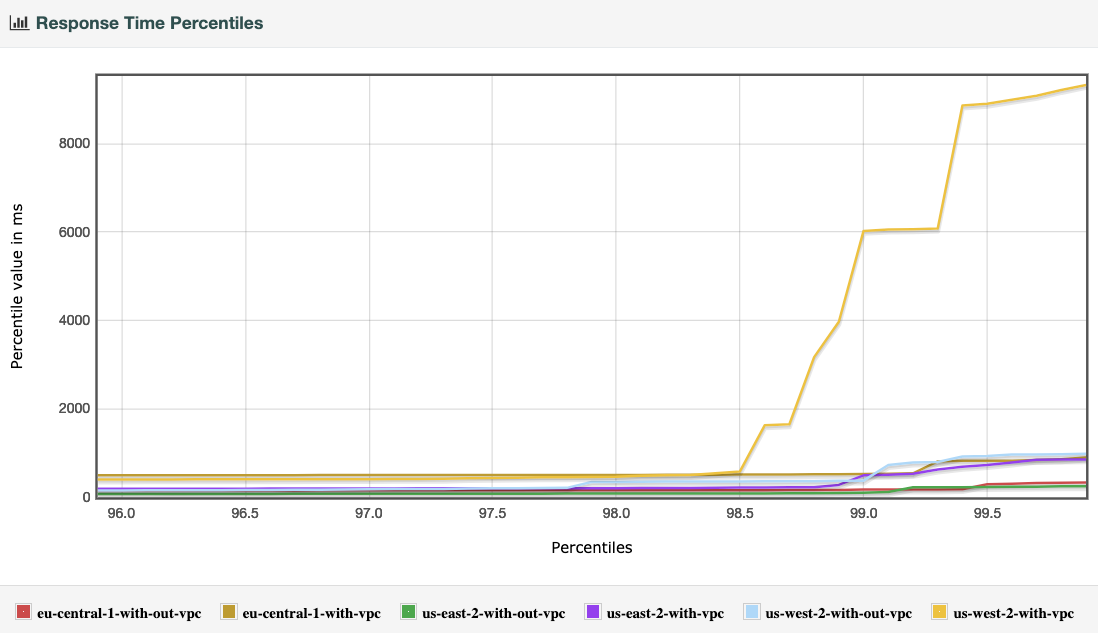
Results
Clearly the Oregon (us-west-2) lambda with VPC is spiking from 450ms to 9000ms. But we don’t see much difference in other two regions even with concurrent requests hitting the APIs.
Conclusion
It is super exciting to see the improvements that AWS team is bringing in various directions to this lambda architecture. With these improvements, Serverless technology will soon be obvious choice for even more use cases where previously people dropped its use because of the cold start issue.
At LeanTaaS, we are increasingly adopting the serverless technology in various uses cases. Recently we started building an entire application just with lambdas and its related technologies which triggered the need for this evolution. Sadly, we are currently in Oregon (us-west-2) region and we are eagerly waiting for the AWS team to rollout these improvements.